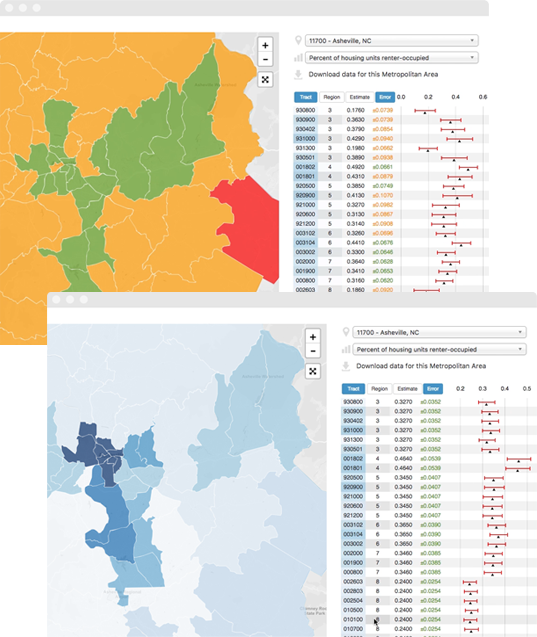
Data quality and the American Community Survey
The American Community Survey (ACS) is the largest survey of US households (3.5 million homes contacted each year) and is the principal source for neighborhood scale information about the US population. The ACS is used to allocate billions in federal spending and is a critical input to social scientific research in the US. However, estimates from the ACS can be highly unreliable. For example, in over 72% of census tracts, the estimated number of children under 5 in poverty has a margin of error greater than the estimate (e.g 100 kids in poverty +/- 150). Uncertainty of this magnitude complicates the use of social data in policy making, research, and governance.
Our project presents a way to reduce the margins of error in survey data via the creation of new geographies, a process called regionalization. Technical details of this paper and example implementations are described in this PLOSOne Paper. This website presents the data from 388 metropolitan statistical areas, before and after the regionalization process, in order to explain, demonstrate, and circulate our results and the data.
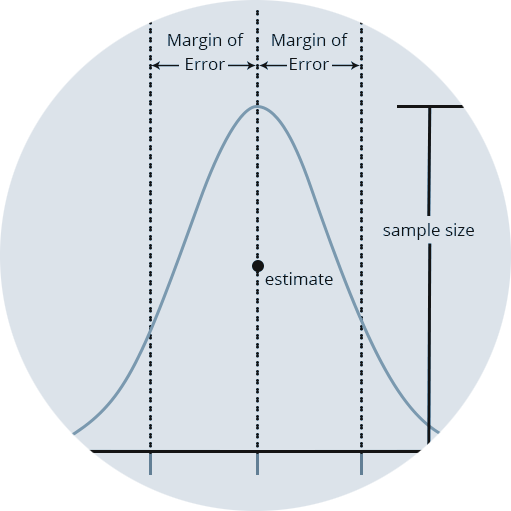
What is Margin of Error?
Each ACS estimate has a corresponding margin of error (MOE). The MOE measures how much the estimate might vary relative to the population value, given a certain confidence level. The ACS uses a confidence level of 90%. For example, if the estimate of median household income for a particular census tract is $50,000 with an MOE of $10,000, then we are 90% confident that the actual median household income for that tract is between $40,000 and $60,000. If the MOE was $40,000, than that range would balloon to $10,000 to $90,000, giving us low confidence that the estimate is accurately capturing the actual income level.
Regionalization
Regionalization is a process of combining neighboring polygons into “regions” based on a set of goals. In this case the goals are to combine census tracts 1) with similar socioeconomic attributes and 2) so that overall estimate uncertainty is reduced. Joining tracts together increases the sample size and thus generally reduces the overall uncertainty on the estimates for the combined tracts. We continue to combine similar tracts until all the estimates in all the regions have met a data quality threshold.

Publications & Source code
Spielman, S., Folch, D. Reducing Uncertainty in the American Community Survey through Data-Driven Regionalization. PLoS ONE, vol. 10, issue 2 (2015) Published by Public Library of Science.
Regionalizations built using 2008-2012 ACS data.
Data and source code is MIT Licensed and can be accessed at Github.